Hadoop安装与配置
Hadoop概述
Hadoop从2.x开始,原生组件主要为如下:
- Hadoop HDFS: 分布式存储
- Hadoop MapReduce: 分布式计算
- Hadoop Yarn: 资源协调组件
- Hadoop Common: 通用组件包
并且对于Hadoop集群中的每个主机,又可以分为如下身份:
- HDFS
- NameNode: 可以在内存中存储分布式数据的元数据(metadata)
- Secondary NameNode: 是NameNode节点的辅助节点,可以定期合并FSImage和Edits
- DataNode: 存储具体的分布式数据内容的节点
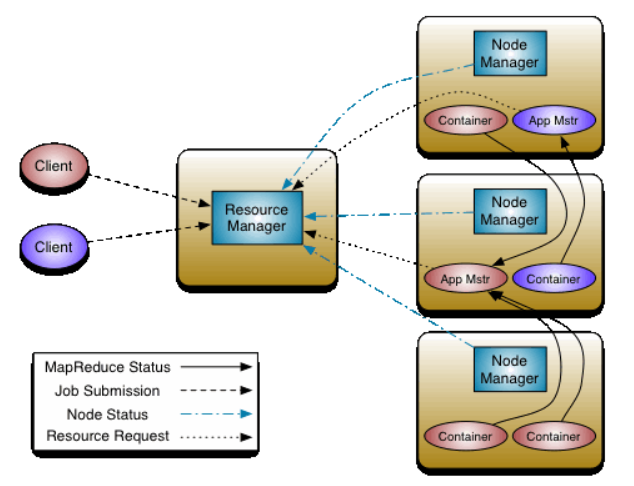
- Yarn
- ResourceManager: 资源分配调度的主节点
- NodeManager: 负责处理具体任务
- ApplicationMaster: 负责某个MR任务的监控和容错
- Container: 对节点资源的抽象
- MapReduce
- Map: 并行处理输入数据
- Reduce: 对Map结果汇总
Hadoop3.x分布式安装
假设目前我们有三台主机,其分别为
| servername | ip | function |
|---|---|---|
| hadoop-vm-1 | 172.37.4.156 (Master) | NameNode/SourceManager/DataNode/NodeManager |
| hadoop-vm-2 | 172.37.4.157 | SecondaryNameNode/DataNode/NodeManager |
| hadoop-vm-3 | 172.37.4.158 | DataNode/NodeManager |
配置主机和环境
- 为所有主机安装JDK8环境
Hadoop需要在JDK环境下运行,请参照Ubuntu常用环境为所有主机安装JDK8并配置依赖。
sudo apt-get install openjdk-8-jdk
sudo vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
source /etc/profile
- 关闭所有主机防火墙
sudo ufw disable
- 为所有主机创建用户和用户组
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop
- 为所有主机的hadoop用户添加权限
sudo vim /etc/sudoers
%sudo ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) NOPASSWD:ALL
sudo chmod -R 777 /opt
- 为所有主机配置网络
vim /etc/hosts
172.37.4.156 hadoop-vm-1
172.37.4.157 hadoop-vm-2
172.37.4.158 hadoop-vm-3
- 配置免密登录
在Master(hadoop-vm-1)上创建密匙并分布到从节点上从而实现免密登录:
sudo apt-get install ssh pdsh
ssh-keygen -t rsa
ssh-copy-id hadoop-vm-2
ssh-copy-id hadoop-vm-3
解压安装Hadoop
- 下载Hadoop二进制文件
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
tar -zxvf hadoop-3.2.2.tar.gz
- 配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
HDFS配置集群
- 配置
./etc/hadoop/core-site.xml:
<configuration>
<!-- 指定HDFS的NameNode地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-vm-1:9000</value>
</property>
<!-- Hadoop运行时的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data/tmp</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
- 配置
./etc/hadoop/hdfs-site.xml:
<!-- HDFS副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- nnWeb端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop:9870</value>
</property>
<!-- 2nnWeb端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9868</value>
</property>
YARN配置
- 配置
./etc/hadoop/yarn-site.xml:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
- 配置
./etc/hadoop/mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
所有主机同步配置
scp /opt/hadoop/etc hadoop-vm-2:/opt/hadoop
scp /opt/hadoop/etc hadoop-vm-3:/opt/hadoop
Hadoop运行启动
- 首先需要导入Java的运行环境
export JAVA_HOME=/opt/jdk
- 启动HDFS
./bin/hdfs namenode -format # 第一次启动需要格式化NameNode
./bin/hdfs --daemon start namenode #secondarynamenode
./bin/hdfs --daemon start datanode
jps
jps将显示具体的Java正在运行的进程,启动成功后,查看HDFS系统可以访问: http://localhost:9870/dfshealth.html
- 启动YARN
./bin/yarn --daemon start resourcemanager
./bin/yarn --daemon start nodemanager
YARN可以通过访问: http://hadoop-vm-1:8088/
通过jps可以查看当前伪集群是否启动完成,具体进程应当包含如下:
2289 DataNode
4866 NodeManager
2183 NameNode
4603 ResourceManager